文章来源 :Python Django+SQL+Pandas+Pyecharts自建在线数据分析平台(一) 作者 :ccpic 感谢 :感谢作者 ccpic 分享的优质内容,本网页主要用于学习知识的存档备份,欢迎点击原网页支持作者。
本篇是系列文章的第4篇:
(一)需求分析&技术实现
(二)初步搭建Django环境
(三)页面布局&Django模板
(五)前端表单交互
(六)Ajax异步传参与加载
(七)前端数据格式的处理
(八)DataTables接管前端表格
(九)Pyecharts实现交互图表
(十)静态图表的展示
(十一)“导出数据至Excel”功能
(十二)添加和配置缓存
(十三)用户登录系统
(十四)部署Django至生产环境
在前两章关注架构的搭建后,把目光拉回到数据的处理这边。我们希望能继续贯彻第一、二章的核心思路,使用SqlAlchemy从服务器调取数据,然后Pandas将数据处理成我们想要的结果,再渲染到第三章创建的display.html模板去。不同于第二章末尾的简单例子,这次我们会着重于Pandas处理数据的部分,争取呈现出一些更加丰富有价值的结果。
涉及数据就必然与业务牵扯上关系,行业与行业之间是差别极大的。这里只能把实际情况写下来,作举一反三之用。
Dummy测试数据链接:https://share.weiyun.com/q1EZl8lW 密码:xaw3kg
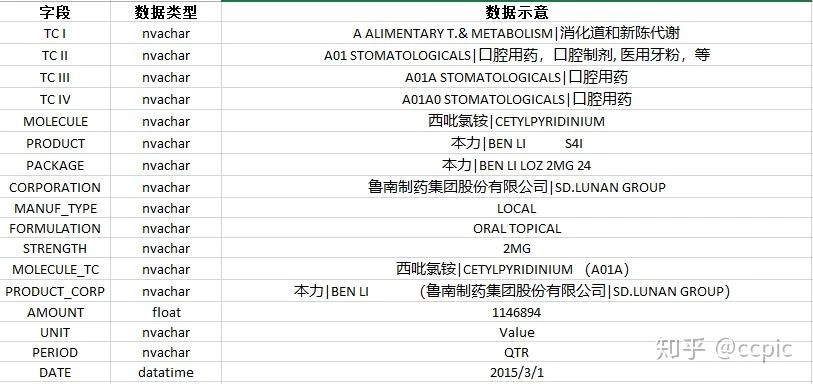
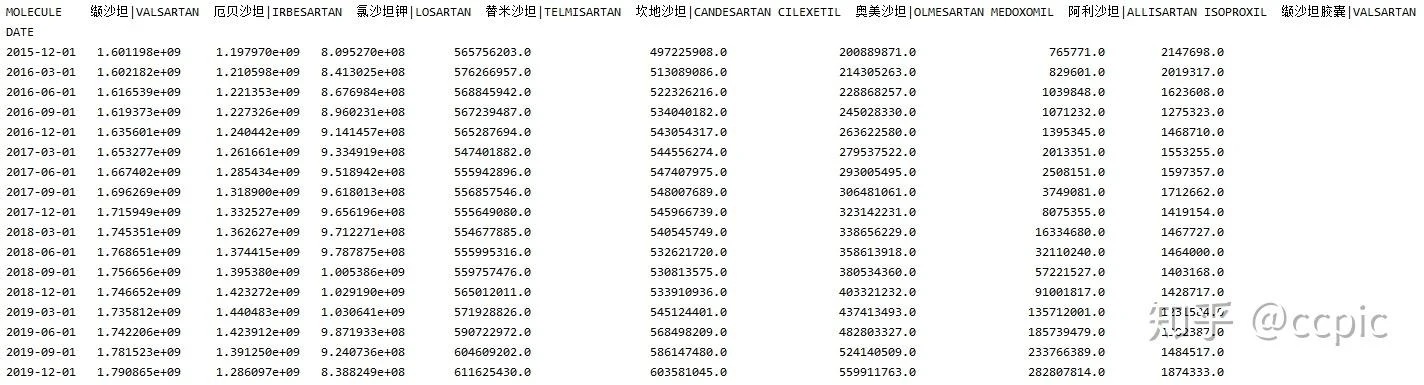
在动手写程序之前,还是应当把我们的数据字段分析透彻,这是一份药物销售数据:
观察之后,我们可以把这些字段分为四类。
属性字段 - 前13个字段是描述这条记录中主体药品的属性,包括分类,化合物通用名,剂型,生产公司等。指标字段 - AMOUNT是每行数据的唯一量化指标字段筛选字段 - UNIT,PERIOD字段则是描述量化指标范围的。UNIT区分该指标是销售额,销售量(盒数)或者销售量(片数);PERIOD区别该指标是滚动年还是季度。日期字段 - DATE,很好理解无需解释了。
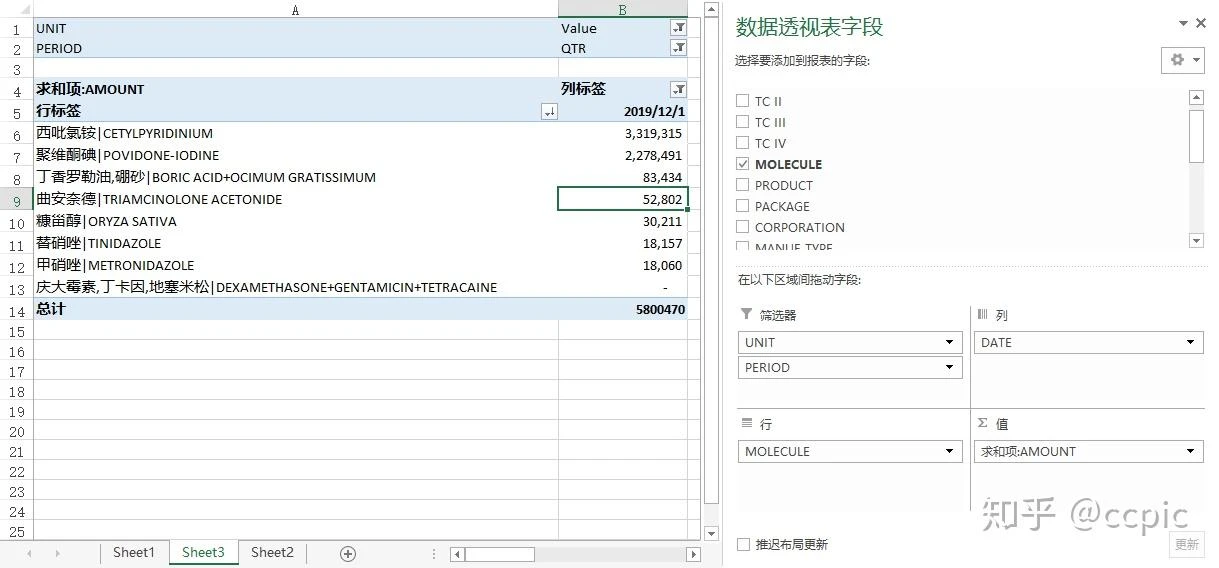
这么分类对于厘清分析思路是很重要的,我们尝试用同样的数据手动拉个Excel数据透视表加深我们的理解:
仔细品味以上数据透视表右下角的设置和左边结果,我们可以得出:
属性字段 - 其中有至少一个属性字段是作为我们分析的breakout的(如品类竞争,品牌竞争,剂型分布),这个字段适合放在数据透视表的列或行。多个分析目标可以嵌套。其他的非分析目标的字段可以酌情作为筛选。指标字段 - AMOUNT是我们汇总统计的量化对象,这个字段是永远需要放在数据透视表的值那里,汇总方式大部分时候是求和。筛选字段 -UNIT和PERIOD是永远需要优先筛选的,且一定是单选。因为把销售额和销售量相加的量化指标没有任何意义,把滚动年和季度相加的时间段也不符合逻辑。所以这两个字段需要永远存在于数据透视表的筛选器,且有一个已选项。日期字段 - DATE很微妙,它在一些横截面数据分析时(如最新xx,同比增长)是个筛选字段:
DATA在横截面数据分析时是筛选字段
但她在趋势分析时又经常作为数据透视的行或列出场,作为结果的一个维度。
DATE在数据分析时经常以数据透视的行/列(面板数据x轴)为角色出场
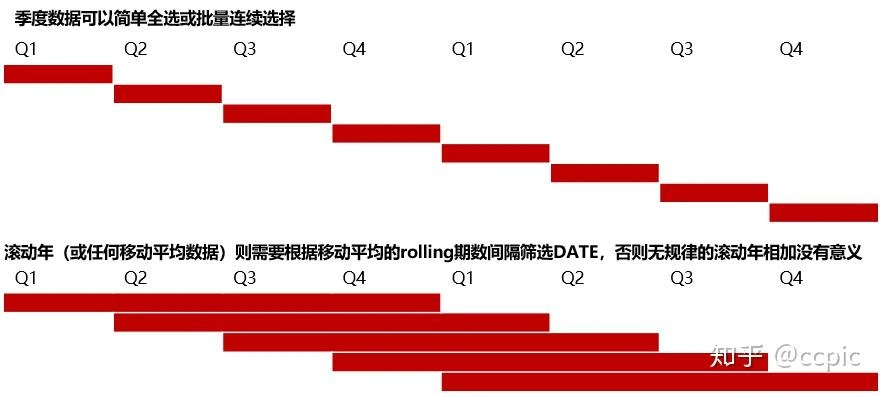
DATE还有一个特殊地方是它的筛选特别是多选遇到移动平均数据时要非常小心,必须在一定规则下进行筛选,见下方的示意图。
我认为做以上如此多的纸上谈兵的工作是有价值的,能快速帮助我们明确以下一些问题:
明确如何编写从服务器提取数据的Sql语句 明确Pandas处理数据的一些细节,如使用pivot_table方法时value, index, column, aggfunc等参数分别是什么 明确前端未来数据筛选时的表单属性,如单选和多选的区别,必填和可选的区别
下面开始实际操作。我的思路还是用SQL尽可能精确地筛选数据,再由Pandas根据需求把数据做各种处理。个人觉得抛开运算速度,Pandas在应对数据处理的各种实际操作时更加友善和高效。
根据上方的分析,我们有两个字段是必须提前做筛选的,PERIOD字段和UNIT字段,其他筛选字段则不确定。因此我们的取数SQL可以暂时写成这样:
def sqlparse (period, unit, filter_sql=None ): sql = "Select * from %s Where PERIOD = '%s' And UNIT = '%s'" % (DB_TABLE, period, unit)  if filter_sql is not None : sql = "%s And %s" % (sql, filter_sql) return sql
未来跟前端结合后更复杂的SQL语句拼接会写成下面这个趋势
def sqlparse (context ): sql = "Select * from %s Where PERIOD = '%s' And UNIT = '%s'" % \ (DB_TABLE, context['period_selected' ], context['unit_selected' ]) return sql
假设我们关心一类药ARB,它是治疗高血压的主流药物血管紧张素Ⅱ受体阻滞剂,我们关心这个市场滚动年的销售额,调用上方的sqlparse方法则可生成需要的sql语句,并依然使用Pandas的read_sql_query语句读取:
sql = sqlparse('MAT' , 'Value' , " [TC III] = 'C09C ANGIOTENS-II ANTAG, PLAIN|血管紧张素II拮抗剂,单一用药'" ) df = pd.read_sql_query(sql, ENGINE)
此时只是对原始数做第一步筛选,数据结构并没有变,我们使用Pandas的pivoted_table方法快速透视数据获取结果。还记得文章之前对各个字段的分析,这里要据此为每个参数选择合适的字段:
import numpy as np... pivoted = pd.pivot_table(df, values='AMOUNT' , index='DATE' , columns='MOLECULE' , aggfunc=np.sum )
此时的数据被透视为下方的时间序列格式,这个结果某些输出已经可以直接使用了,做进一步其他数据处理也异常方便:
比如我们想知道整体市场的规模,增长率和CAGR(年复合增长率),根据我们上方对DATE字段的分析,可以做如下操作:
def get_kpi (df ): market_total = df.sum (axis=1 ) market_size = market_total.iloc[-1 ] market_gr = market_total.iloc[-1 ] / market_total.iloc[-5 ] - 1 market_cagr = (market_total.iloc[-1 ] / market_total.iloc[0 ]) ** (0.25 ) - 1 if market_size == np.inf or market_size == -np.inf: market_size = "N/A" if market_gr == np.inf or market_gr == -np.inf: market_gr = "N/A" if market_cagr == np.inf or market_cagr == -np.inf: market_cagr = "N/A" return { "market_size" : market_size, "market_gr" : market_gr, "market_cagr" : market_cagr, } print (get_kpi(pivoted))
结果为:
ARB市场的年销售额为60亿,年增长率+3.1%,年复合增长率+5.2%
我们可以继续以这个思路生成更复杂的结果:
def ptable (df ): df_share = df.transform(lambda x: x/x.sum (), axis=1 ) df_gr = df.pct_change(periods=4 ) df_gr.dropna(how='all' ,inplace=True ) df_gr.replace([np.inf, -np.inf], np.nan, inplace=True ) df_latest = df.iloc[-1 ,:] df_latest_diff = df.iloc[-1 ,:] - df.iloc[-5 ,:] df_share_latest = df_share.iloc[-1 , :] df_share_latest_diff = df_share.iloc[-1 , :] - df_share.iloc[-5 , :] df_gr_latest = df_gr.iloc[-1 ,:] df_total_gr_latest = df.sum (axis=1 ).iloc[-1 ]/df.sum (axis=1 ).iloc[-5 ] -1 df_ei_latest = (df_gr_latest+1 )/(df_total_gr_latest+1 )*100 df_combined = pd.concat([df_latest, df_latest_diff, df_share_latest, df_share_latest_diff, df_gr_latest, df_ei_latest], axis=1 ) df_combined.columns = ['最新滚动年销售额' , '净增长' , '份额' , '份额同比变化' , '同比增长率' , 'EI' ] return df_combined print (ptable(pivoted))
市场内各通用名分子的表现一览
把以上数据处理过程整合入views.py里的index方法,此时我们可以有更丰富的context传入display.html模板:
def index (request ): sql = sqlparse('MAT' , 'Value' , " [TC III] = 'C09C ANGIOTENS-II ANTAG, PLAIN|血管紧张素II拮抗剂,单一用药'" ) df = pd.read_sql_query(sql, ENGINE) pivoted = pd.pivot_table(df, values='AMOUNT' , index='DATE' , columns='MOLECULE' , aggfunc=np.sum ) if pivoted.empty is False : pivoted.sort_values(by=pivoted.index[-1 ], axis=1 , ascending=False , inplace=True ) kpi = get_kpi(pivoted) context = { "market_size" : kpi["market_size" ], "market_gr" : kpi["market_gr" ], "market_cagr" : kpi["market_cagr" ], 'ptable' : ptable(pivoted).to_html() } return render(request, 'chpa_data/display.html' , context)
在前端display.html模板里写入对应context的django tag,并用Semantic UI的tab语法稍作布局。
{% extends "chpa_data/analysis.html" % } {% block display % } <div class ="ui pointing secondary menu" > <a class ="item active" data-tab ="total" > <i class ="circle icon" > </i > 总体表现</a > <a class ="item" data-tab ="competition" > <i class ="trophy icon" > </i > 竞争现状</a > </div > <div class ="ui tab segment active" data-tab ="total" > <h3 class ="ui header" > <div class ="content" > 定义市场当前表现 <div class ="sub header" > KPIs</div > </div > </h3 > <div class ="ui divider" > </div > <div class ="ui small three statistics" > <div class ="statistic" > <div class ="value" id ="value_size" > {{ market_size } } </div > <div class ="label" id ="label_size_unit" > 滚动年金额 </div > </div > <div class ="statistic" id ="div_gr" > <div class ="value" id ="value_gr" > {{ market_gr } } </div > <div class ="label" > 同比增长 </div > </div > <div class ="statistic" id ="div_cagr" > <div class ="value" id ="value_cagr" > {{ market_cagr } } </div > <div class ="label" > 4年CAGR </div > </div > </div > </div > <div class ="ui tab segment" data-tab ="competition" > <h3 class ="ui header" > <div class ="content" > 最新横断面KPI一览 <div class ="sub header" > 数据表格</div > </div > </h3 > <div class ="ui divider" > </div > <div class ="ui container" id ='result_table' style ="width: 100%; overflow-x: scroll; overflow-y: hidden;" > {{ ptable|safe } } </div > </div > <script > $('.pointing.secondary.menu .item' ).tab (); </script > {% endblock % }
因为css框架的语法都是应用类的比较简单,在本系列文章我较少讲解Semantic UI,后续有不少朋友反应这里有个坑需要注意:
要保证Semantic UI的tab功能正常,需要保证ui pointing secondary menu这个Div下的item和后续对应的ui tab segment,两者的data-tab属性一一对应,并且两者都有且只有一个active。
现在再在浏览器里访问127.0.0.1:8088/chpa/index,界面会变为:
如果您使用了我提供的随机dummy数据测试,这里结果不一样是正常的,因为我写此文时使用了原始真实数据
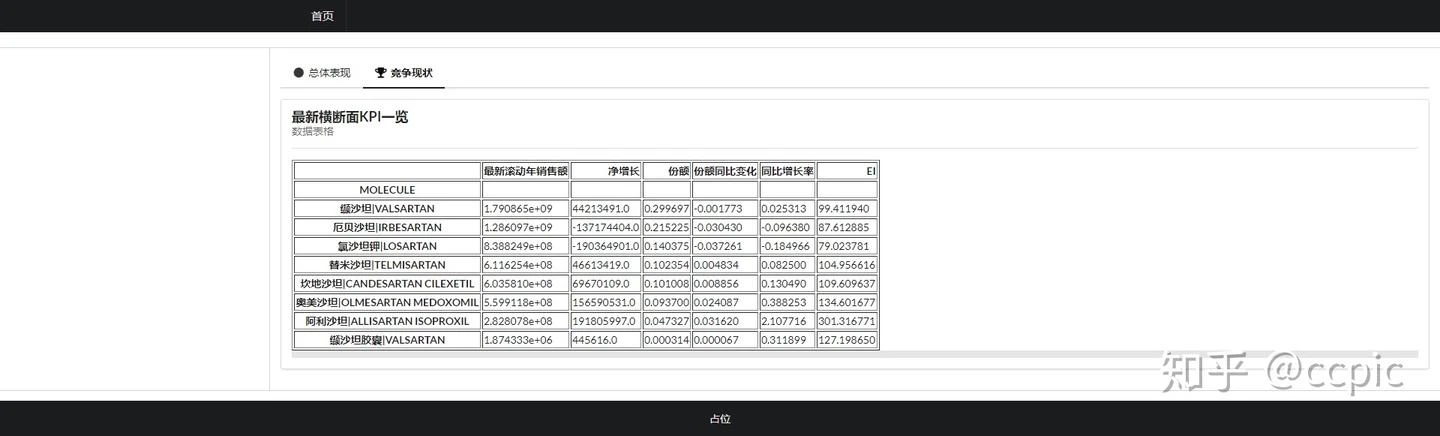
点击“竞争现状”那个tab,会出现我们渲染过来的ptable:
如果您使用了我提供的随机dummy数据测试,这里结果不一样是正常的,因为我写此文时使用了原始真实数据
至此我们已经初步取得了我们想要的数据分析结果,除了更丰富的分析维度,我们还缺少交互、格式化和可视化,这些留待以后讨论。
下一篇请移步: